

Abstract
我們提出了一種使用單一深度神經網路檢測影像中的物體的方法。我們的方法名為 SSD,將 bounding boxes 的輸出空間離散化為一組 default boxes,在每個 feature map location 具有不同的長寬比和尺度。在預測時,網路會針對每個 default box 中每個物體類別的存在情況產生分數,並對 box 進行調整以更好地匹配物體形狀。
此外,該網路結合了具有不同解析度的多個 feature maps 的預測,以自然地 handle 各種尺寸的物體。 SSD 相對於需要物體 proposals 的方法來說很簡單,因為它完全消除了 proposal 生成和後續像素或 feature resampling 階段,並將所有計算封裝在單一網路中。這使得 SSD 易於訓練,並且可以直接整合到需要檢測 computation (組件) 的系統中。
在 PASCAL VOC、COCO 和 ILSVRC 資料集上的實驗結果證實,SSD 與利用額外物體 proposal 步驟的方法相比,具有競爭性的 accuracy,並且速度更快,同時為 training 和 inference 提供統一的 framework。對於 300×300 輸入,SSD 在 Nvidia Titan X 上以 59 FPS 的 VOC2007 測試中實現了 74.3% mAP1;對於 512×512 輸入,SSD 實現了 76.9% mAP,優於同類最先進的 Faster R-CNN 模型。與其他單階段方法相比,即使輸入影像尺寸較小,SSD 也具有更高的 accuracy。程式碼位於: https://github.com/weiliu89/caffe/tree/ssd。
Introduction
自從 Selective Search work 到 PASCAL VOC、COCO 和 ILSVRC 檢測的當前領先結果以來,該流程在檢測 benchmarks (基準)上一直占主導地位。(全部基於 Faster R-CNN)
儘管這些先進的物體檢測系統具有準確性和複雜性,但它們有一個顯著的缺點: 它們是計算密集的,而且即使使用高端 hardware,對於即時應用程式來說也太慢。這意味著它們需要大量的處理能力,這使得它們不適合:
- 嵌入式系統: 這些電腦系統是較大設備的一部分,處理能力有限 (如相機、汽車或小型家用電器中的系統)。
- 即時應用: 在需要立即回應的場景中 (例如: 在視訊監控、自動駕駛車輛或互動系統中),這些系統由於計算量大而速度太慢。
這些方法的檢測速度通常以每幀秒 (SPF) 來衡量,即使是最快的高精度 detector Faster R-CNN,也只能以每秒 7 幀 (FPS) 的速度運作。
研究人員嘗試透過最佳化偵測過程的不同階段 (例如如何假設 bounding boxes,或如何擷取和分類 features) 來提高物體偵測模型的速度。雖然可以使這些系統更快,但這樣做通常會導致 accuracy 顯著下降。 這是至關重要的一點,因為在許多物體偵測應用 (例如自動駕駛車輛或安全系統) 中,保持高 accuracy 與快速處理影像一樣重要。
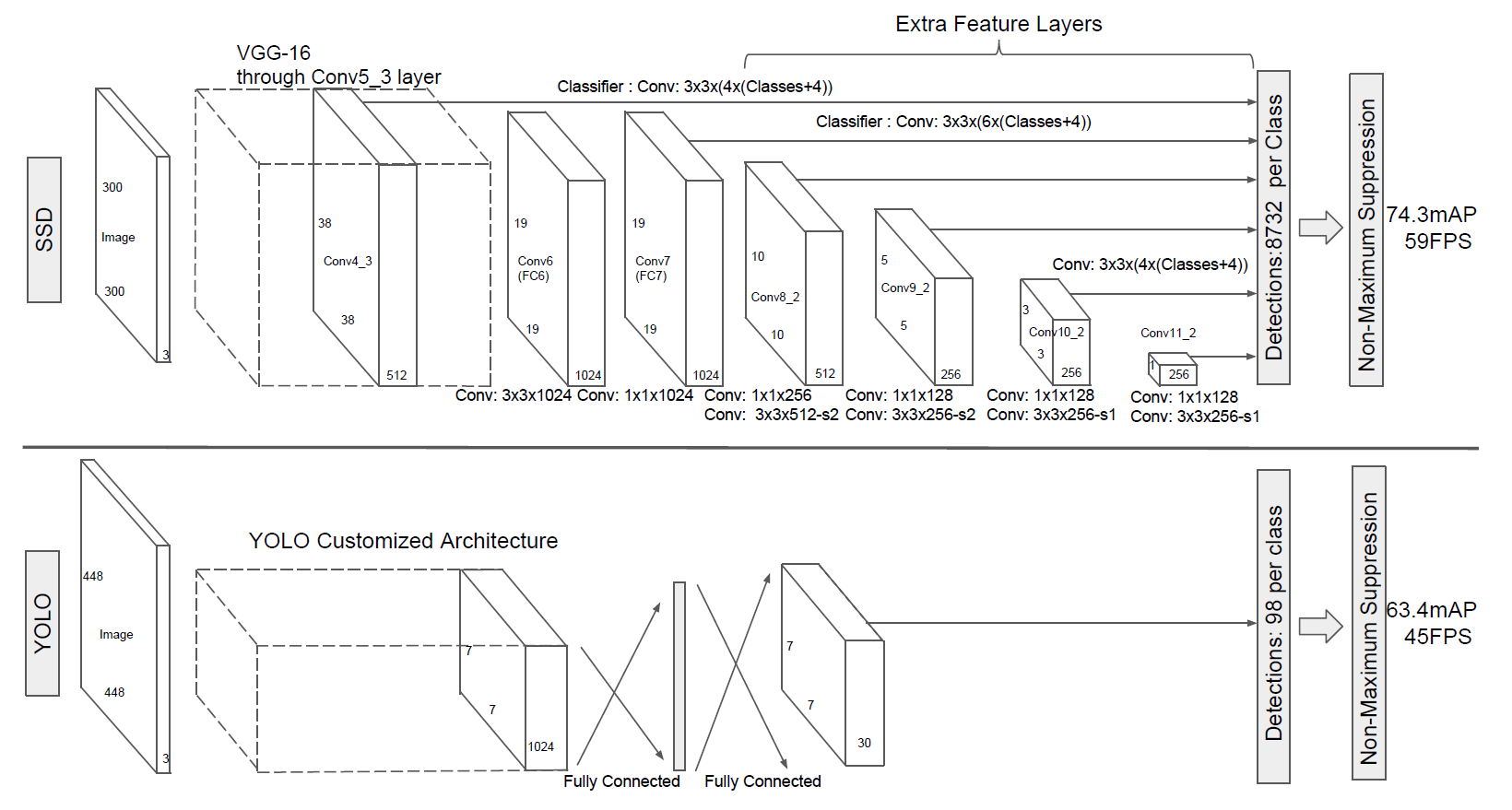
本文提出了第一個基於深度網路的目標 detector,它不會為 bounding box 假設重新取樣像素或特徵,並且與重新取樣的方法一樣 accurate。這使得 high-accuracy 檢測的速度顯著提高 (在 VOC2007 測試中,59 FPS,mAP 74.3%,而 Faster R-CNN 7 FPS,mAP 73.2% 或 YOLO 45 FPS,mAP 63.4%)。
速度的根本改進來自於消除 bounding box proposals (提議) 和隨後的像素或特徵重新取樣階段。我們並不是第一個這樣做的人,但透過添加一系列改進,我們設法比以前的嘗試顯著提高 accuracy。我們的改進包括使用:
- Bounding Box 假設無需重新取樣: 傳統的物體檢測方法,如 Faster R-CNN,會產生多個 bounding box proposals,然後對其進行 refine (提煉) 以準確定位目標。 這涉及對像素或特徵進行重新取樣 (即,以不同的比例或視角多次查看影像的相同部分)。SSD 方法消除了這個步驟。
- 小型卷積濾波器: 預測 bounding box location 中的物體類別和偏移 (offsets)。
- 單獨的 predictors (filters): 進行不同的縱橫比檢測,以及將這些 filters 應用於網路後期的多個 feature maps,以執行多尺度檢測。
- 多尺度檢測: SSD 將這些 filters 應用於網路的多個層。 這使得系統能夠檢測不同尺度 (大小) 的物體而無需重新取樣。
透過這些修改,特別是使用多層進行不同尺度的預測,我們可以使用相對較低解析度的輸入來達到 high-accuracy,從而進一步提高檢測速度。
雖然這些貢獻單獨看來可能很小,但我們注意到,最終的系統提高了 PASCAL VOC 即時檢測的 accuracy,從 YOLO 的 63.4% mAP 提高到 SSD 的 74.3% mAP。與最近備受矚目的 Residual Networks 研究相比,這在檢測 accuracy 方面有了更大的相對改進。此外,顯著提高高品質檢測的速度,可以擴大電腦視覺有用的設定範圍。
我們的貢獻總結如下:
- 我們介紹了 SSD,這是一種適用於多個類別的 single-shot detector (單次檢測器),比之前最先進的 single shot detectors (YOLO) 更快,並且更準確,實際上與執行顯式 region proposals 和 pooling 的較慢技術一樣準確 (包括 Faster R-CNN 技術)。
- SSD 的kernel是使用應用於 feature maps 的小型卷積 filters,預測一組固定的 default bounding boxes 的類別分數和 box offsets。
- 為了實現高檢測 accuracy,我們從不同尺度的 feature maps 產生不同尺度的預測,並按縱橫比明確分離預測。
- 這些設計功能可實現簡單的 end-to-end training 訓練和高 accuracy,即使在低解析度輸入影像上也是如此,從而進一步改善速度與 accuracy 的權衡。
- 實驗包括在 PASCAL VOC、COCO 和 ILSVRC 上,評估的不同輸入大小的模型,進行時序和準確性分析,並與一系列最新的 state-of-the-art approaches (最先進方法) 進行比較。
The Single Shot Detector (SSD)
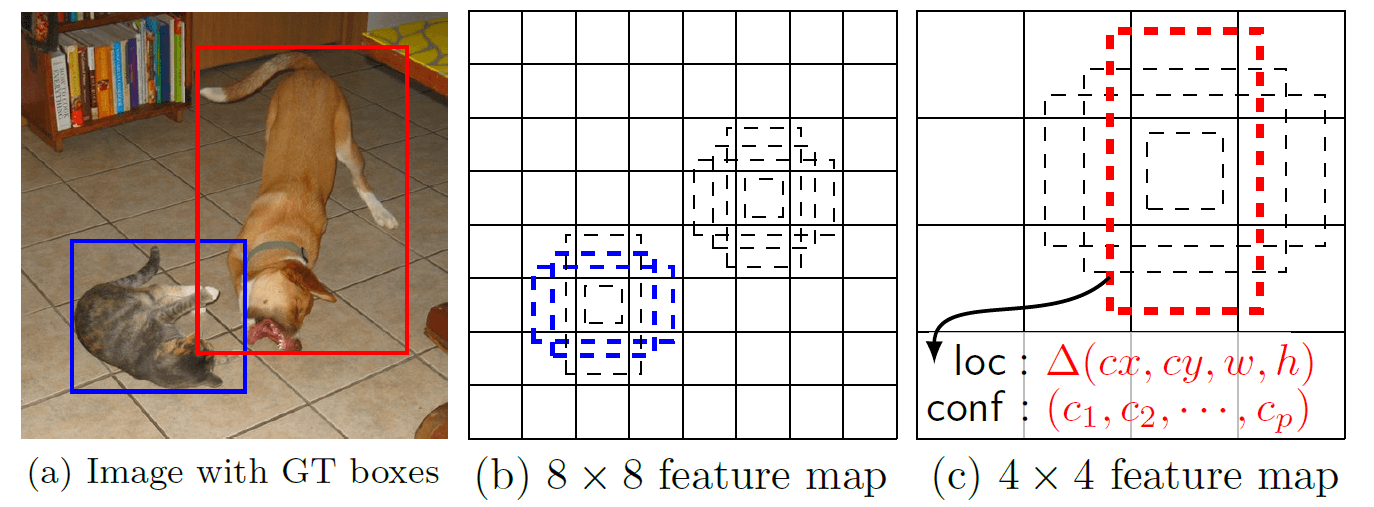
對於每個 default boxe,我們預測所有物體類別的形狀 offsets 和 confidence ($(c1,c2,\cdots,cp)$)。在訓練時,我們首先將這些 default boxes 與 ground truth boxes 進行配對。與真實情況密切相關的框被視為positives (正確的檢測),其餘的則被視為 negatives (不正確的檢測或沒有物體)。
例如: 我們將兩個 default boxes 與貓匹配,一個與狗匹配,這兩個 default boxes 被視為 positives (正例),其餘的被視為 negatives (負例)。模型損失是 localization 損失 (例如: Smooth L1) 和 confidence 損失 (例如: Softmax) 之間的加權和。
2.1 Model
SSD 方法基於 feed-forward 卷積網路,該網路向前處理影像 (輸入到輸出),產生固定大小的 collection of bounding boxes 和分數,指示這些 boxes 中是否存在物體類別。此後,使用 non-maximum suppression (非極大值抑制) 步驟將這些檢測 refine 為最終集合 (最終檢測)。
SSD 網路的初始層改編自影像分類領域成功的架構。 這些層被 'truncated' (截斷),這意味著網路的分類部分被刪除,它們作為檢測物體的基礎 (在任何分類層之前 truncated)。我們將其稱為 base network。(我們使用 VGG-16 網路作為基礎,但其他網路也應該產生良好的結果。) 然後,我們在網路上新增輔助結構以產生具有以下主要特徵的檢測:
- 用於檢測的多尺度 feature maps:
我們將卷積 feature layer 加入到截斷的 base network 的末尾。這些附加層的大小逐漸減小,並允許在多個尺度上預測檢測。每個 feature layer 用於預測檢測的卷積模型都是不同的,與 Overfeat 和 YOLO 等依賴單一尺度 feature map 的模型相比,SSD 能夠更有效地處理各種大小的物體。
- 用於檢測的多尺度 feature maps:
我們將卷積 feature layer 加入到截斷的 base network 的末尾。這些附加層的大小逐漸減小,並允許在多個尺度上預測檢測。每個 feature layer 用於預測檢測的卷積模型都是不同的,與 Overfeat 和 YOLO 等依賴單一尺度 feature map 的模型相比,SSD 能夠更有效地處理各種大小的物體。
對於具有 p 個 channels 的大小為 m×n 的 feature layer,用於預測潛在檢測參數的基本元素是一個 3×3×p 小 kernel,它產生類別的分數,或相對於 default box 座標的形狀 offset。在應用 kernel 的每個 m×n locations 處,它都會產生一個輸出值。Bounding box offset 輸出值是相對於每個 feature map 位置的 default box location 來測量的 (請參閱 YOLO 的架構,該架構在此步驟中使用中間全連接層而不是卷積濾波器)。
- Default boxes 和長寬比:
我們將一組 default bounding boxes 與每個 feature map cell 相關聯,用於網路頂部的多個 feature maps。default boxes 以卷積方式平鋪 feature map,以便每個 box 相對於其對應 cell 的位置是固定的。在每個 feature map cell 中,我們預測相對於 cell 中 default box 形狀的 offsets,以及指示每個 boxes 中,是否存在類別實例的每個類別分數。
具體來說,對於給定 location 處的 k 個 box 中的每個 box,我們計算 c 類分數以及相對於原始 default box 形狀的 4 個 offsets。這導致總共 (c + 4)k 個濾波器應用於 feature map 中每個 location,從而為 m×n feature map 產生 (c + 4)kmn 個輸出。
有關 default boxes 的說明,請參閱圖 1。我們的預設框與 Faster R-CNN 中使用的 anchor boxes 類似,但我們將它們應用於不同解析度的多個 feature maps。在多個 feature maps 中允許不同的預設框形狀,可以讓我們有效地離散可能的輸出 box 形狀的空間。
2.2 Training
匹配策略 (Matching strategy): 在訓練過程中,我們需要確定哪些 default boxes 對應於 ground truth 檢測,並相應地訓練網路。對於每個 ground truth box,我們都會從 default boxes 中進行選擇,default boxes 的 location、長寬比和尺度各不相同。
最初將每個真實物體 (ground truth box) 與具有最高重疊的 default box (透過 Jaccard overlap 測量,類似於 MultiBox 中做的) 進行配對。然後,與 MultiBox 不同,如果 Jaccard overlap 高於 0.5 (50%),SSD 也會將任何 default box 與 ground truth box 進行匹配。 這使得網路能夠識別與真實物體重疊的多個潛在 boxes,允許網路預測多個重疊 default boxes 的高分,而不是要求它只選擇重疊最大的一個。這簡化了學習問題,從而使學習過程變得更容易。
訓練目標: SSD 訓練目標源自 MultiBox 目標,但擴展為處理多個物體類別。設 $x_{ij}^{p}=\left \{ 1,0 \right \}$ 為第 i-th 個 default box 與類別 p 的第 j-th 個 ground truth box 進行比對的 indicator (指標)。在上面的配對策略中,我們可以讓 ${\textstyle \sum_{i}^{}} x_{ij}^{p}\ge 1$。總體目標損失函數是 localization 損失 (loc) 和 confidence 損失 (conf) 的加權和:
$$L(x,c,l,g) = \frac{1}{N} (L_{conf} (x, c) + \alpha L_{loc}(x,l,g)) \tag{1}$$其中 N 是匹配的 default boxes 的數量。如果 N = 0,則將損失設為 0。定位損失是預測 box (l) 和 ground truth box (g) 參數之間的 Smooth L1 損失。與 Faster R-CNN 類似,我們遞迴 default bounding box (d) 的中心 (cx, cy) 及其寬度 (w) 和高度 (h) 的 offsets。
$$\begin{gather*} L_{loc}(x,l,g) =\sum_{i\in Pos}^{N}\sum_{m\in\left \{cx,cy,w,h \right \} }^{} x_{ij}^{k}smooth_{L1} (l_{m}^{i} - \hat{g}_{m}^{j}) \\ \hat{g}_{j}^{cx} =g_{j}^{cx}-{d}_{i}^{cx}/{d}_{i}^{w} \qquad \hat{g}_{j}^{cy} =g_{j}^{cy}-{d}_{i}^{cy}/{d}_{i}^{h} \tag{2}\\ \hat{g}_{j}^{w} =\log_{}{\frac{g_{j}^{w} }{d_{i}^{w} }} \qquad \hat{g}_{j}^{h} =\log_{}{\frac{g_{j}^{h} }{d_{i}^{h} }} \\ \end{gather*}$$Confidence 損失是多類別 confidences (c) 上的 softmax 損失,和透過 cross validation (交叉驗證) 將權重項 α 設定為 1。
$$\begin{gather*} L_{conf}(x,c) =-\sum_{i\in Pos}^{N} x_{ij}^{p}\log_{}{\hat{c}_{i}^{p}}-\sum_{i\in Neg}^{}\log_{}{\hat{c}_{i}^{0}} \enspace \text{where} \enspace \hat{c}_{i}^{p}=\frac{\exp c_{i}^{p} }{ {\textstyle \sum_{p}^{}\exp c_{i}^{p}} } \tag{3} \\ \end{gather*}$$localization 損失: 這是使用 Smooth L1 損失計算的,它測量物體的預測 bounding box 和實際 bounding box 之間的差異。 預測包括 box 的中心、寬度和高度。
Confidence 損失: 這是使用多個類別的 confidence 分數的 softmax 損失來計算的。 網路預測 default box 中,包含特定類別物體的 confident。 總體損失函數是這兩個損失的加權和,其中考慮了匹配的 default boxes 的數量 (N)。 如果沒有符合的 boxes (N=0),則損失設定為零。
為 default boxes 選擇尺度和長寬比: 為了處理不同的物體比例,一些方法建議以不同尺寸處理影像,然後組合結果。然而,透過利用單一網路中多個不同 layers 的 feature maps 進行預測,我們可以模擬出相同的效果,同時還可跨所有物體尺度,共享參數。
先前的工作已經表明,使用較低 layers 的 feature maps 可以提高 semantic segmentation 品量,因為較低的 layers 能捕獲輸入物體的更多精細細節。同樣,文獻 [12] 表明,添加從 feature map 中池化的 global context,可以幫助 smooth segmentation 結果。受這些方法的啟發,我們使用下部和上部 feature maps 進行檢測。圖 1 顯示了在 framework 中,使用的兩個範例 feature maps (8×8 and 4×4)。在實踐中,我們可以使用更多的,而且計算 overhead 很小。
下層 feature maps 捕捉更精細的細節,改善物體偵測,而上層則添加 context。 SSD 使用兩者來提高偵測精度。
眾所周知,網路中不同 levels 的 feature maps 具有不同的 receptive field (感受野) 大小 (實證的)。幸運的是,在SSD framework 內,default boxes 不需要對應於每一層的實際 receptive fields。我們設計了 tiling (鋪平) of default boxes,使特定的 feature maps 學會回應物體的特定尺度。假設我們想使用 m 個 feature maps 進行預測。每個 feature map 的 default boxes 的尺度計算如下:
$$s_{k} =s_{min}+\frac{s_{max}-s_{min}}{m-1} (k-1), \quad k \in \left [ 1,m \right ] \tag{4}$$其中 $s_{min}=0.2$,$s_{smax}=0.9$,這表示最低 layer 的尺度為 0.2,最高 layer 的尺度為 0.9,且其間的所有 layers 均規則間隔。
我們對 default boxes 施加不同的長寬比,並將它們表示為 $a_{r}\in{1, 2, 3, 1/2 , 1/3 }$。我們可以計算每個 default box 的寬度 ($w_{k}^{a} =s_{k}\sqrt{a_{r}}$) 和高度 ($h_{k}^{a} =s_{k}/\sqrt{a_ {r}}$)。對於長寬比為 1 的情況,我們還新增了一個尺度為 ${s}'_{k}=\sqrt{s_{k}s_{k+1}}$ 的 default box,導致每個 feature map location 有 6 個 default box。
我們將每個 default box 的中心設定為 ($\frac{i+0.5}{\left | f_{k} \right | }, \frac{j+0.5}{\left | f_{k} \right | }$),其中 $\left | f_{k} \right |$ 是第 k 個方形 feature map 的大小, $i,j \in \left [ 0,\left | f_{k} \right| \right)$。在實踐中,人們還可以設計 default box 的分佈以最適合特定的資料集。如何設計最佳的 tiling 也是一個懸而未決的問題。
透過組合不同尺度的所有 default boxes 的預測,以及許多 feature maps 所有 locations 的長寬比,我們擁有一組多樣化的預測,涵蓋各種輸入物體的大小和形狀。例如: 在圖 1 中,狗與 4×4 feature map 中的 default box 匹配,但不與 8×8 feature map 中的任何 default box 匹配。這是因為這些 boxes 具有不同的尺度,並且與狗 box 不匹配,因此在訓練期間被視為 negatives (負例)。
Hard negative mining: 在匹配步驟之後,大多數 default boxes 都是 negatives (負例),特別是當可能的 default boxes 數量很大時。這引入了 positive and negative 訓練範例之間的顯著不平衡。我們沒有使用所有的 negative examples,而是使用每個 default box 的最高 confidence loss 對它們進行排序,並選擇最上面的,以便 negatives and positives 之間的比例最多為 3:1。我們發現這會帶來更快的最佳化和更穩定的訓練。
這種不平衡的問題在於,它可能會導致 model 表現不佳,因為 model 可能會偏向預測 negatives。為了抵消這一點,Hard Negative Mining 涉及選擇資訊最豐富的 negative samples。它根據 positive 的 confidence (通常是損失) 對所有 negative samples 進行排序,並選擇最重要的樣本 (model 預測最不正確的樣本)。這確保了 model 從最具挑戰性的範例中學習,從而提高其區分 positives and negatives 的能力。通常,negatives and positives 之間會保持一定的比例 (例如: SSD 中的 3:1),以保持訓練過程的平衡。
Data augmentation: 為了使 model 對各種輸入物體的大小和形狀更加穩健,每幅訓練影像都會透過以下選項之一進行隨機取樣:
- 使用整個原始輸入影像。
- 隨機取樣一個 patch (片段),使其與物體的 minimum jaccard 重疊為 0.1、0.3、0.5、0.7 或 0.9。
- 隨機取樣一個 patch。
每個取樣的 patch 的大小是原始影像大小的 $[0.1, 1]$,長寬比在 $1/2$ 和 $2$ 之間。如果 ground true box 的中心位於取樣 patch 中,我們將保留它的重疊部分。在上述取樣步驟之後,每個取樣 patch 都被調整為固定大小,並以 0.5 的機率水平翻轉,應用一些類似於文獻 [14] 中,描述的 photometric distortions (光度扭曲)。
常見的 photometric distortions 包括:1. 調整亮度、對比和飽和度。2. 加入noise。3. 變更色彩平衡或執行色彩抖動。 4. 改變清晰度。
Experimental Results
Base network: 我們的實驗都是基於 VGG16,它是在 ILSVRC CLS-LOC 資料集上進行預訓練的。與 DeepLab-LargeFOV 網路類似,我們將 fc6 和 fc7 轉換為卷積層,對 fc6 和 fc7 的參數進行子取樣,將 pool5 從 2×2 − s2 更改為 3×3 − s1,並使用 à trous algorithm 填補 "holes"。我們刪除所有 dropout 層和 fc8 層。
我們對結果模型進行 fine-tune ,使用SGD、 initial learning rate $10^{−3}$ 、momentum 0.9 、權重衰減 0.0005 和 batch size 32 。每個資料集的 learning rate 衰減策略略有不同,我們將在稍後描述詳細資訊。完整的訓練和測試程式碼是基於 Caffe 構建,並開源於: https://github.com/weiliu89/caffe/tree/ssd。
à trous 在法語中是 "有孔" 的意思,是用來描述該技術的原始術語,特別是在 wavelet transforms (小波變換) 的背景下。然而,隨著這個概念在卷積神經網路領域中被使用和流行,術語 dilated convolution 得到了更廣泛的使用。
3.1 PASCAL VOC2007
在此資料集上,我們在 VOC2007 test (4952 張影像) 上與 Fast R-CNN 和 Faster R-CNN 進行比較。所有方法都在相同的預訓練 VGG16 網路上進行 fine-tune。
圖 2 顯示了 SSD300 模型的架構詳細資訊。我們使用 Conv4_3、Conv7 (fc7)、Conv8_2、Conv9_2、Conv10_2 和 Conv11_2 來預測 location 和 confidences。我們在 conv4_3 上設定比例為 0.1 的 default box (對於 SSD512 模型,我們新增額外的 conv12_2 進行預測,將 $s_{min}$ 設為 0.15,在 conv4_3 上設定 0.07)。
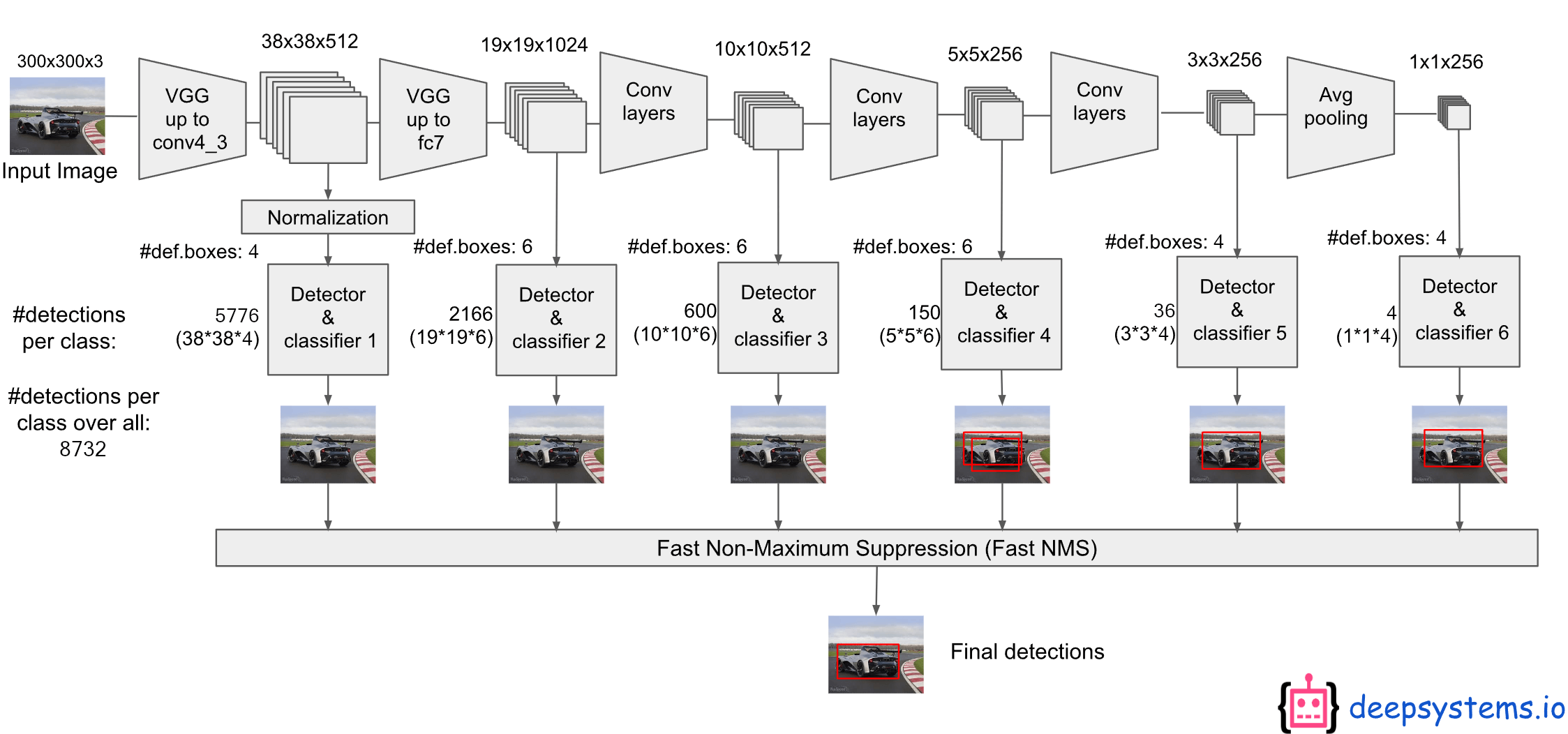
我們使用 "xavier" 方法初始化所有新加入的卷積層的參數。對於 conv4_3、conv10_2 和 conv11_2,我們僅在每個 feature map location 關聯 4 個 default boxes - 省略 1/3 和 3 的長寬比。對於所有其他 layers, 我們按照 "第 2.2 節" 中的描述放置了 6 個 default boxes。
如 [12] 中指出的,由於與其他 layers 相比,conv4_3 具有不同的 feature 尺度,因此我們使用 [12] 中引入的 L2 normalization 技術將 feature map 中每個 location 的 feature norm (範數) 縮放到 20,並學習 back propagation 的縮放。我們使用 $10^{−3}$ learning rate 進行 40k 次 iterations,然後繼續使用 $10^{−4}$ 和 $10^{−5}$ 進行 10k 次 iterations 訓練。當在 VOC2007 trainval 上訓練時,表 1 顯示我們的低解析度 SSD300 model 已經比 Fast R-CNN 更準確。當我們在更大的 512×512 輸入影像上訓練 SSD 時,它的準確率更高,比 Faster R-CNN 提高了 1.7% mAP。
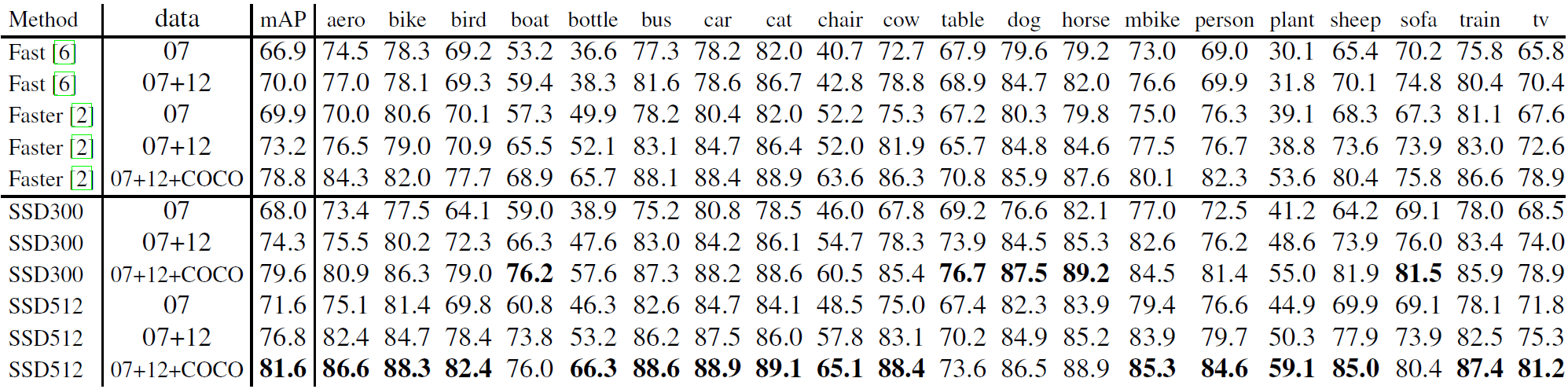
data: "07": VOC2007 trainval,"07+12": VOC2007 和 VOC2012 trainval 的 union。 "07+12+COCO": 首先在 COCO trainval35k 上訓練,然後在 07+12 上進行 fine-tune。
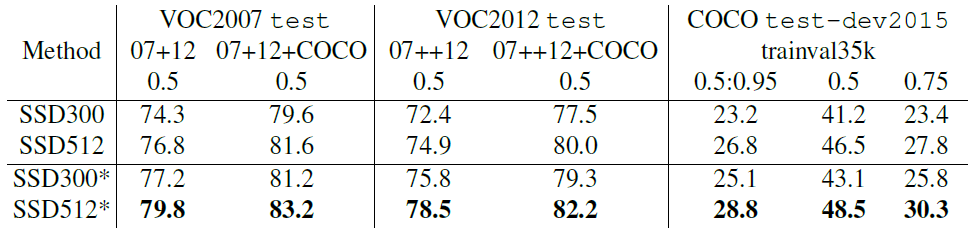
如果我們用更多資料訓練 SSD (即 07+12),我們會發現 SSD300 已經比 Faster R-CNN 好 1.1%,SSD512 好 3.6%。如果我們採用 "第 3.4 節" 中所述的在 COCO trainval35k 上訓練的模型,並使用 SSD512 在 07+12 資料集上進行 fine-tuning,我們將獲得最佳結果:81.6% mAP。
Xavier initialization 隨機設定 layer 的權重,但值是從 mean 為零和特定 variance 的分佈中提取的。此 variance 取決於該 layer 的輸入和輸出 units 的數量。對於具有 $n_{\text{in}}$ 個輸入和 $n_{\text{out}}$ 個輸出 units 的 layer,權重範圍通常會是 $[-a, a]$, 其中 $a = \sqrt{\frac{6}{n_{\text{in}} + n_{\text{out}}}}$,或來自 mean 為 0 和 variance 為 $\frac{2}{n_{\text{in}} + n_{\text{out}}}$ 的常態分佈。
這種初始化方法有助於緩解深度神經網路中, vanishing (消失) or exploding (爆炸) gradients 的問題,特別是在使用 sigmoid 或 tanh activation functions 的架構中。對於使用 ReLU activations 的架構,通常首選稱為 He initialization 的變體。
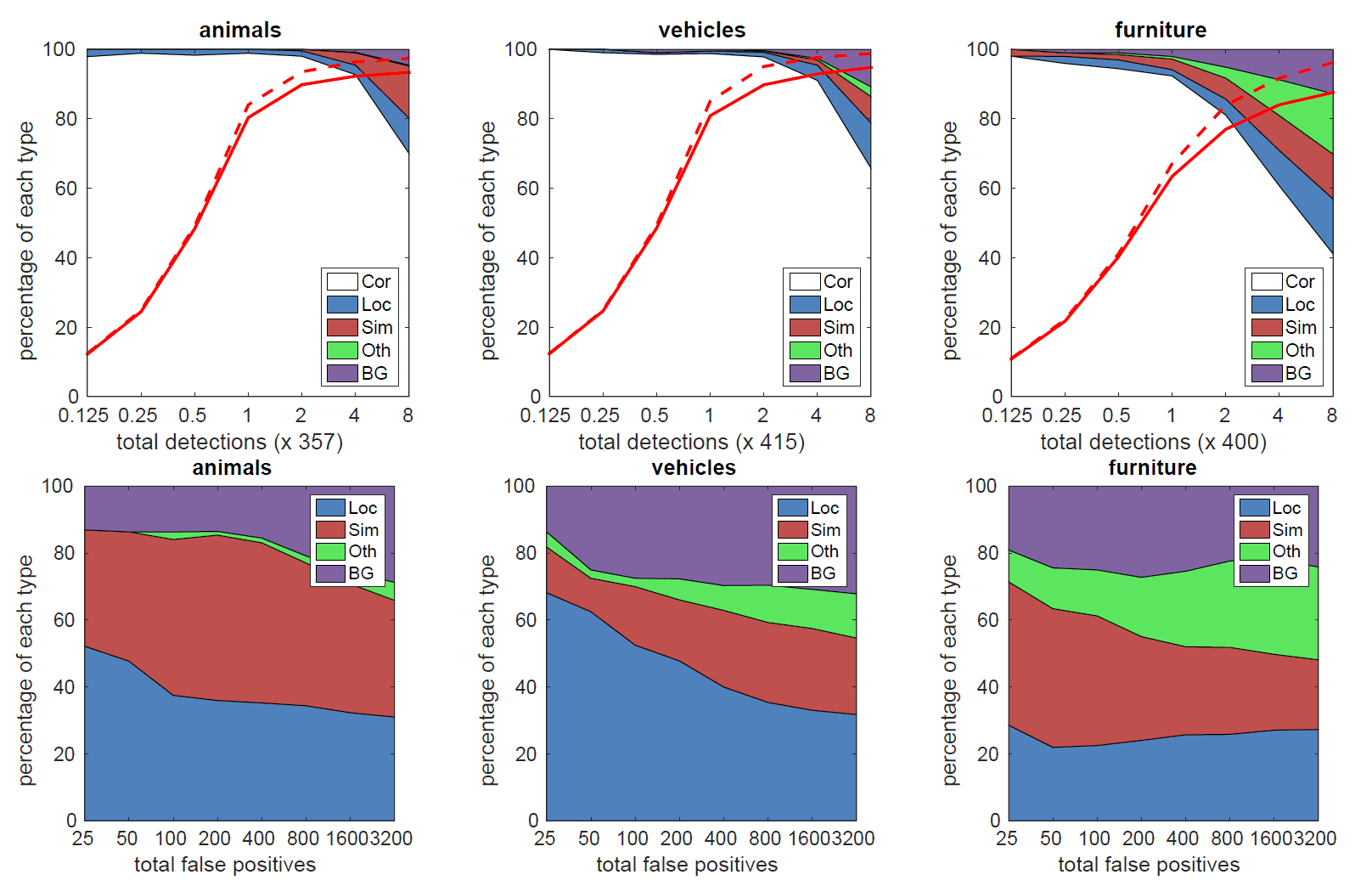
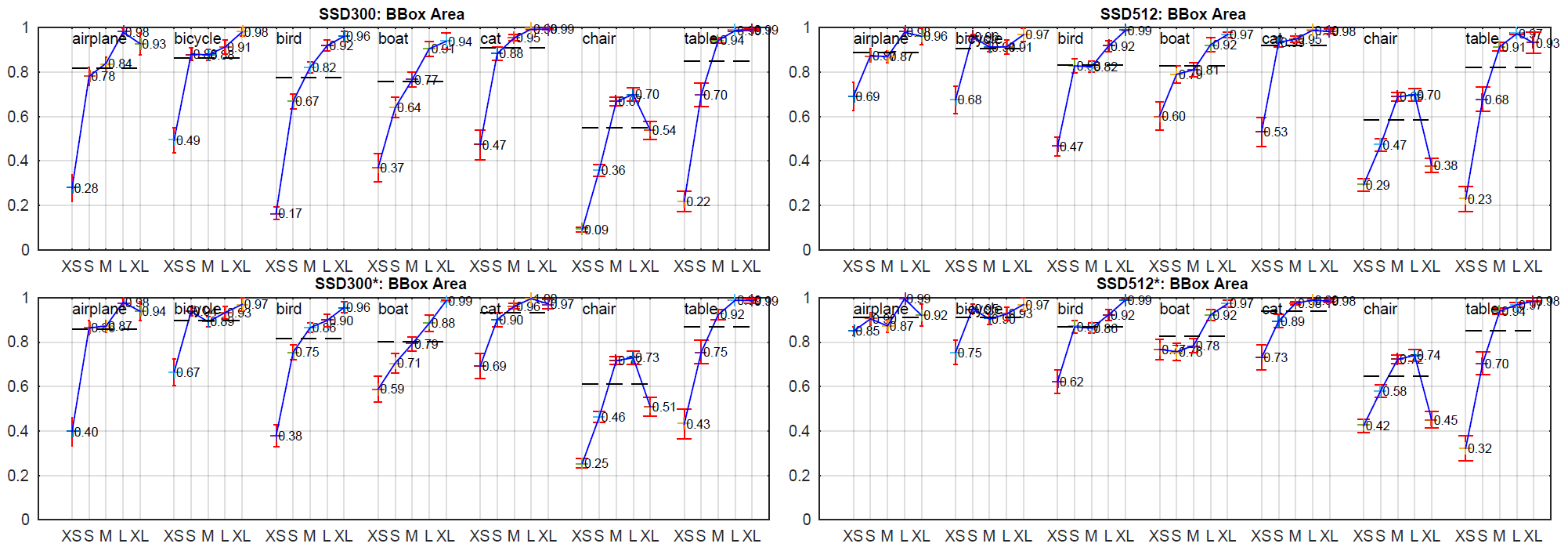
為了更詳細地了解我們的兩個 SSD 模型的效能,我們使用了 [21] 中的檢測分析工具。圖 3 顯示 SSD 可以高品質檢測各種物體類別(大白色區域)。其大部分可信檢測都是正確的。Recall 約為 85-90%,"弱"標準下 (0.1 jaccard overlap) 要高得多。與R-CNN相比,SSD 的 localization error 較小,這表明 SSD 可以更好地定位物體,因為它直接學習遞迴物體形狀,並對物體類別進行分類,而不是使用兩個 decoupled (解耦) 的步驟。
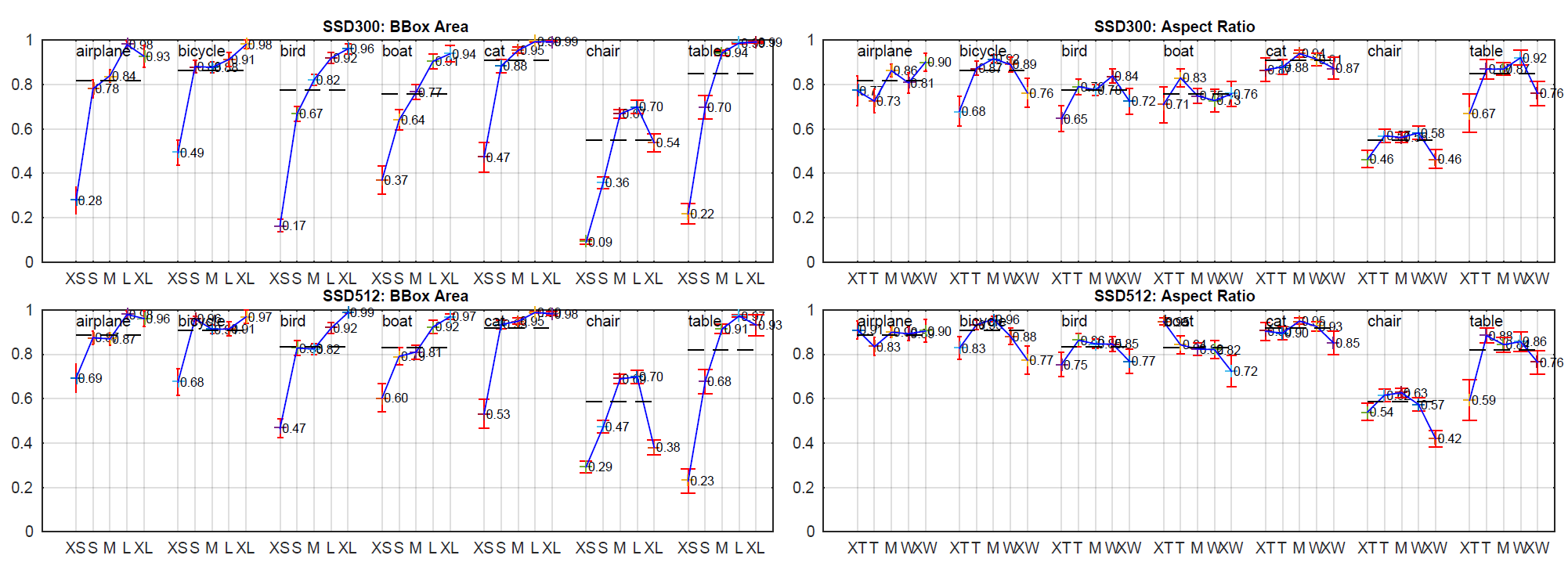
BBox Area: XS=特小; S=小; M=中; L=大; XL = 超大號。長寬比: XT=超高/窄; T=高; M=中; W=寬; XW = 超寬。
然而,SSD 對相似的物體類別 (尤其是動物) 有更多的困惑,部分原因是我們共享多個類別的 locations。圖 4 顯示 SSD 對 bounding box 大小非常敏感。換句話說,它在較小物體上的表現比在較大物體上差得多。這並不奇怪,因為這些小物體甚至可能在 top layers 沒有任何資訊。增加輸入尺寸可以幫助改善小物體的偵測 (例如: 從 300×300 到 512×512) ,但仍有很大的改進空間。從積極的一面來看,我們可以清楚地看到 SSD 在大型物體上的表現非常出色。它對於不同的物體長寬比非常 robust,因為我們在每個 feature map location 使用不同長寬比的 default boxes。
3.2 Model analysis
為了更好地了解 SSD,我們進行了對照實驗,來檢查每個 component (組成) 如何影響性能。對於所有實驗,我們使用相同的設定和輸入大小 (300×300),除了對設定或元件進行指定變更之外。
Data augmentation 至關重要: Fast 和 Faster R-CNN 使用原始影像和水平翻轉來訓練。我們使用了一種更廣泛的取樣策略,類似於 YOLO。表 2 顯示,採用這種取樣策略,我們可以將 mAP 提高 8.8%。我們不知道我們的取樣策略會對 Fast 和 Faster R-CNN 帶來多大好處,但它們可能受益較少,因為它們在分類過程中使用了 feature pooling 步驟,該步驟在設計上對 object translation 相對地 robust 。

Feature pooling,通常涉及稱為 Region of Interest (RoI; 感興趣的區域) pooling 的過程。它的工作原理如下:
1. Feature Map 提取: 首先,影像透過卷積神經網路,輸出高維 feature map。此 feature map 包含輸入影像的豐富的、抽象的表示。
2. Region Proposals: 在 Faster R-CNN 等架構中,region proposal network (RPN; 區域提議) 用於預測潛在的物體 boundary boxes 或 regions of interest (RoIs),其中物體可能位於其中。
3. RoI Pooling: 對於每個 proposed region,需要處理該區域對應的 feature map,以進行最終的分類和 bounding box refinement (精煉)。然而,這些區域可以具有不同的形狀和大小,而後續的 fully connected layers 需要固定大小的輸入。
RoI pooling 在這裡發揮作用: 它將每個 RoI 內的 features 轉換為固定大小的 feature map (例如: 7x7)。這是透過將 RoI 劃分為固定數量的 segments (水平和垂直),然後對每個 segment 中的 features 進行 max-pooling 來完成的。
Default box 形狀越多越好: 如 "第 2.2 節" 所述,預設情況下我們每個 location 使用 6 個 default boxes。如果我們刪除長寬比為 1/3 和 3 的 boxes,效能會下降 0.6%。透過進一步刪除長寬比為 1/2 和 2 的 boxes,效能又下降了 2.1%。使用各種 default box 形狀似乎可以使網路預測 boxes 的任務變得更容易。
à trous 速度很快: 如 "第 3 節" 所述。在圖 3 中,我們使用了子取樣 VGG16 的無孔版本,遵循 DeepLab-LargeFOV 網路。如果我們使用完整的 VGG16,保持 pool5 為 2×2 − s2,並且不對 fc6 和 fc7 的參數進行二次取樣,並添加 conv5_3 進行預測,結果大致相同,但速度慢了約 20%。
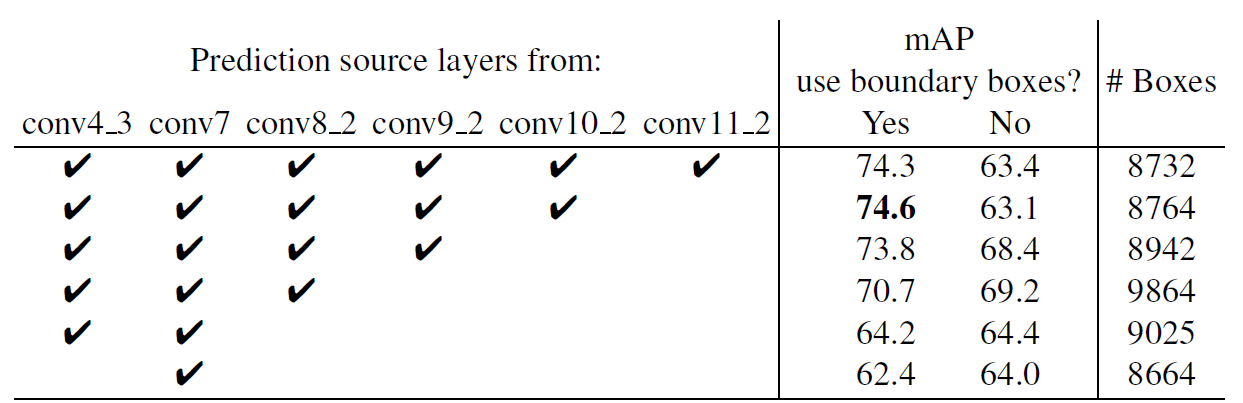
不同解析度的多個輸出 layers 效果更好: SSD 的一個主要貢獻是在不同的輸出 layers 上使用不同尺度的 default boxes。為了衡量所獲得的優勢,我們逐步刪除 layers 並比較結果。為了公平比較,每次刪除一個 layer 時,我們都會調整 default box tiling,以保持 boxes 的總數與原始的相似 (8732)。具體做法是在其餘 layers 上堆疊更多尺度的 boxes,並根據需要調整 boxes 的尺度。我們不會對每種設定的 tiling 進行詳盡的最佳化。
表 3 顯示了 layers 數越少,accuracy 就越低,從 74.3 單調地下降到 62.4。當我們在一個 layer 上堆疊多個尺度的 boxes 時,許多都在影像 boundary (邊界) 上,需要小心處理。我們嘗試了 Faster R-CNN 中使用的策略,忽略邊界上的 boxes 。我們觀察到一些有趣的趨勢。例如: 如果我們使用非常粗糙的 feature maps (例如: conv11_2 (1×1) 或 conv10_2 (3×3)),它會大幅損害效能。原因可能是修剪後我們沒有足夠的大 boxes 來覆蓋大物體。當我們主要使用更精細的解析度 maps 時,效能再次開始提高,因為即使在修剪之後仍然保留足夠數量的大 boxes 。如果我們只使用 conv7 進行預測,性能是最差的,這強化了這樣的資訊: 將不同尺度的 boxes 分佈在不同 layers 上是至關重要的。
此外,由於我們的預測不依賴 [6] 中的 ROI pooling,因此我們在低解析度 feature maps 中不存在 collapsing bins problem [23]。 SSD 架構結合了各種解析度的 feature maps 的預測,以實現與 Faster R-CNN 相當的精度,同時使用較低解析度的輸入影像。
1. Region of Interest (RoI) Pooling: RoI pooling 用於一些物體偵測模型中,將每個 proposed region (提議區域) 內的 features 轉換為固定大小的 feature map。這對於將這些 features 輸入 fully connected layers,以進行分類和 bounding box 遞歸是必要的。
2. 低解析度 Feature Maps: 在某些情況下,匯集 RoIs 的 feature maps (卷積層的輸出) 可能是低解析度的。這種低解析度可能是由於影像的初始低解析度、網路中的 down-sampling 或因為 RoI 本身很小。
3. Collapsing Bins Problem: 當將 RoI pooling 應用於這些低解析度 feature maps 時,尤其是對於小 RoI,存在使用多個 bins (segments) 的風險,在 pooling 過程中可能會塌陷為單一像素或 feature map 的非常小的區域。發生這種崩潰的原因是沒有足夠的像素,來分佈在固定大小 pooled region 的 bins 中。因此,pooled feature map 可能無法保留足夠的空間資訊來準確表示 RoI 內的物體,從而導致檢測任務的表現較差,尤其是對於小物體。
3.3 PASCAL VOC2012
我們使用與上面基礎 VOC2007 實驗相同的設定,不同之處在於我們使用 VOC2012 trainval 和 VOC2007 trainval and test (21503 張影像) 進行訓練,並在 VOC2012 test (10991 張影像) 上進行測試。我們使用 $10^{−3}$ learning rate 進行 60k 次 iterations 訓練模型,然後使用 $10^{−4}$ learning rate 進行 20k 次 iterations。
表 4 顯示了我們的 SSD300 和 SSD5124 模型的結果。我們看到了與 VOC2007 test 中觀察到的相同的效能趨勢。我們的 SSD300 比 Fast/Faster RCNN 提高了準確性。透過將訓練和測試影像尺寸增加到 512×512,我們的準確率比 Faster R-CNN 提高了 4.5%。與 YOLO 相比,SSD 的準確率明顯更高,這可能是由於在訓練期間使用了來自多個 feature maps 的卷積 default boxes 以及我們的匹配策略。當根據 COCO 訓練的模型進行 fine-tuned,我們的 SSD512 實現了 80.0% mAP,比 Faster R-CNN 高 4.1%。

data: "07++12": VOC2007 trainval 和 test 以及 VOC2012 trainval 的 union。 "07++12+COCO": 首先在 COCO trainval35k 上訓練,然後在 07++12 上進行 fine-tune。
3.4 COCO
為了進一步驗證 SSD framework,我們在 COCO 資料集上訓練了 SSD300 和 SSD512 架構。由於 COCO 中的物體往往比 PASCAL VOC 小,因此我們對所有圖層使用較小的 default boxes。我們遵循 "第 2.2 節" 中提到的策略,但現在我們最小的 default box 的比例為 0.15 而不是 0.2,並且 conv4_3 上的 default box 的比例為 0.07 (例如: 300×300 影像的 21 像素)。(對於 SSD512 model,我們新增額外的 conv12_2 進行預測,將 $s_{min}$ 設為 0.1,並在 conv4_3 上設定 0.04。)
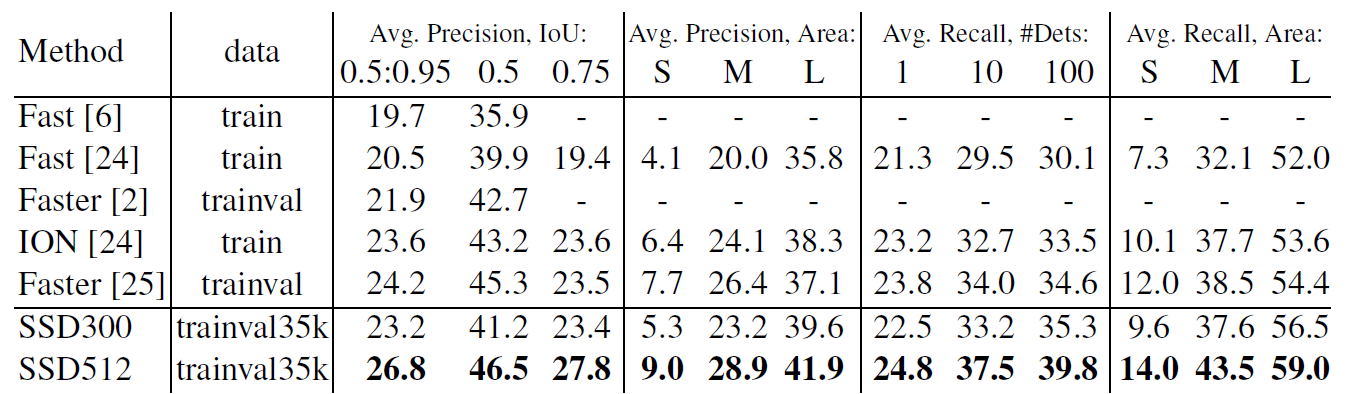
SSD300 具有與 ION 和 Faster R-CNN 類似的 [email protected],但 [email protected] 較差。透過將影像尺寸增加到 512×512,我們的 SSD512 在這兩個標準上都優於 Faster R-CNN 。有趣的是,我們觀察到 SSD512 在 [email protected] 中提高了 4.3%,但在 [email protected] 中僅提高了 1.2%。
我們也觀察到,與 Faster R-CNN 相比 ,對於大物體,SSD512 具有更好的 AP (4.8%) 和 AR (4.6%),但對於小物體,其 AP (1.3%) 和 AR (2.0%) 的改進相對較小。與 ION 相比,大物體和小物體在 AR 方面的改進更加接近 (3.9% 和 5.4%)。我們推測,Faster R-CNN 在使用 SSD 的較小物體上更有競爭力,因為它在 RPN 部分和 Fast R-CNN 部分都執行了兩個 box refinement steps。在圖 5 中,我們展示了使用 SSD512 模型在 COCO test-dev 上的一些檢測示例。

3.5 ILSVRC 初步結果
我們將用於 COCO 的相同網路架構應用於 ILSVRC DET 資料集。我們使用 ILSVRC2014 DET 和 Val1 訓練 SSD300 模型,如文獻 [22] 所用。我們首先使用 $10^{-3}$ learning rate 訓練模型 320k 次 iterations,然後繼續使用 $10^{-4}$ 訓練 80k 次 iterations,並使用 $10^{-5}$ 訓練 40k 次 iterations。我們可以在 val2 set 上實作 43.4 mAP。再次驗證了 SSD是一個高品質即時檢測的通用 framework。
3.6 Data Augmentation 以提高小物體的準確性
如果沒有像 Faster R-CNN 那樣的後續 feature resampling 步驟,對於 SSD 來說,小物體的分類任務相對較難,我們的分析也證明了這一點 (詳見圖 4)。"第 2.2 節" 中描述的 data augmentation 策略有助於顯著提高性能,尤其是在 PASCAL VOC 等小型資料集上。該策略生成的隨機裁切可以看作是一種 "zoom in" operation,可以生成許多更大的訓練示例。
為了實現 "zoom out" operation ,創建更多小的訓練示例,我們首先將影像隨機放置在原始影像大小的 16 倍的畫布上,並填充平均值,然後再進行任何隨機裁剪 operation。因為透過引入這種新的 "擴展" data augmentation 技巧,我們獲得了更多的訓練影像,所以我們必須將訓練 iterations 次數加倍。我們看到多個資料集的 mAP 持續增加了 2%-3%,如表 6 所示。具體而言,圖 6 顯示新的 augmentation 技巧顯著提高了小物體的效能。這項結果強調了 data augmentation 策略對最終模型準確性的重要性。
改進 SSD 的另一種方法是設計更好的 tiling of default boxes,使其位置和尺度更好地與 feature map 上每個位置的 receptive field 對齊。我們把這個留到以後的工作。
3.7 Inference time
考慮到我們的方法產生的大量 boxes,在 inference 過程中有效地執行 non-maximum suppression (nms) 至關重要。透過使用 0.01 的 confidence 閾值,我們可以過濾掉大多數 boxes。然後,我們應用 nms,每類 jaccard overlap 為 0.45,並保留每個影像的前 200 個檢測。
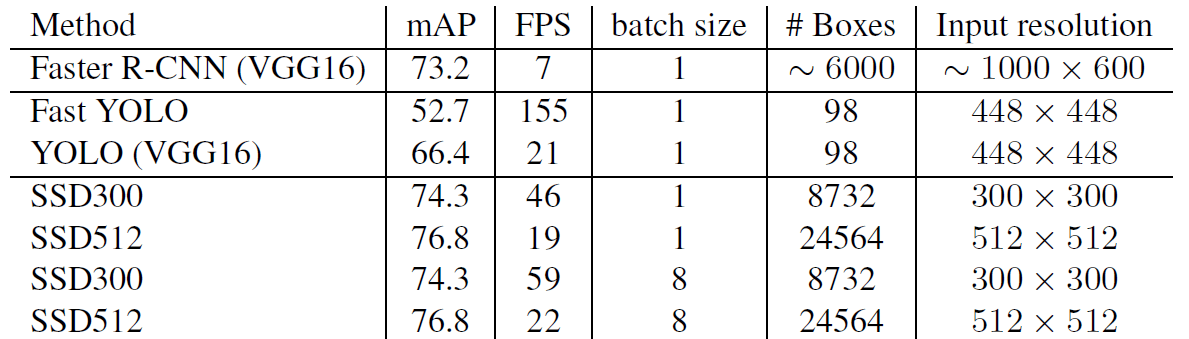
對於 SSD300 和 20 VOC 類別,此步驟每張影像花費約 1.7 毫秒,這接近所有新加入的 layers 所花費的總時間 (2.4 毫秒)。我們使用 Titan X 和 cuDNN v4 以及 Intel Xeon [email protected] 測量 batch size=8 的速度。
表 7 顯示了 SSD、Faster R-CNN 和 YOLO 之間的比較。我們的 SSD300 和 SSD512 方法在速度和準確性方面都優於 Faster R-CNN。儘管 Fast YOLO 可以以 155 FPS 運行,但它的準確度較低,mAP 低了近 22%。據我們所知,SSD300 是第一個達到 70% 以上 mAP 的即時方法。請注意,大約 80% 的轉發時間花費在 base network 上 (在我們的例子中為 VGG16)。因此,使用更快的 base network 甚至可以進一步提高速度,這也可能使 SSD512 模型變得即時。
Related Work
影像中的物體檢測有兩類成熟的方法,一類基於 sliding windows (滑動窗口),另一類基於 region proposal (區域提議) 分類。在卷積神經網路出現之前,這兩種方法的最新技術—— Deformable Part Model (DPM) 和 Selective Search ——具有相當的性能。然而,R-CNN 結合 selective search region proposals 和基於卷積網路的 post-classification (後分類),帶來了巨大改進,之後 region proposal 物體檢測方法變得流行。
原始的 R-CNN 方法已經透過多種方式進行改進。第一組方法提高了 post-classification 的品質和速度,因為它需要對數千種影像作物進行分類,這是昂貴且耗時的。 SPPnet 顯著加快了原始 R-CNN 方法的速度。它引入了一個 spatial pyramid pooling layer (空間金字塔池化層),該 layer 對區域大小和尺度更加 robust,並允許分類 layers 重複使用在多種影像解析度下,根據生成的 feature maps 計算的 features。
Fast R-CNN 擴展了 SPPnet,使其可以透過最小化 confidences 和 bounding box 遞迴的損失,對所有 layers 進行端到端的 fine-tune。(首次在 MultiBox 中引入,用於學習物體性。)
第二組方法使用深度神經網路來提高 proposal 產生的品質。在像 MultiBox 這樣的最新作品中,基於 low-level 影像特徵的 Selective Search region proposals,被直接從單獨的深度神經網路生成的 proposals 所取代。這進一步提高了檢測精度,但導致設定有些複雜,需要訓練兩個具有依賴性的神經網路。
Faster R-CNN 用從 region proposal network (RPN) 中學習的,替換了 selective search proposals,並引入了一種透過交替 finetuning 這兩個網路的 shared convolutional layers 和預測 layers,來將 RPN 與 Fast R-CNN 整合的方法。這種方式,region proposals 用於 pool mid-level features,並且最終分類步驟的成本較低。
我們的 SSD 與 Faster R-CNN 中的 region proposal network (RPN) 非常相似,因為我們也使用一組固定的 (default) boxes 進行預測,類似於 RPN 中的 anchor (錨框)。但我們不是使用這些來 pool features 並且評估另一個分類器,而是同時為每個 box 中的每個物體類別產生一個分數。因此,我們的方法避免了將 RPN 與 Fast R-CNN 合併的複雜性,並且更容易訓練、更快、更容易整合到其他任務中。
另一組方法與我們的方法直接相關,完全跳過 proposal 步驟並直接預測多個類別的 bounding boxes 和 confidences。 OverFeat 是 sliding window 方法的深度版本,在了解底層物體類別的置信度後,直接從最頂層 feature map 的每個 location 預測 bounding box。 YOLO 使用整個最頂層 feature map 來預測多個類別和 bounding boxes (這些類別共享) 的 confidences 。
我們的 SSD 方法屬於此類,因為我們沒有 proposal 步驟,而是使用 default boxes。然而,我們的方法比現有方法更靈活,因為我們可以在不同尺度的多個 feature maps 的每個 feature location 上,使用不同長寬比的 default boxes。如果我們只使用最頂層 feature map 中每個 location 的一個 default box,我們的 SSD 將具有與 OverFeat 類似的架構;如果我們使用整個最頂層的 feature map 並加入一個 fully connected layer 進行預測,而不是使用 convolutional predictors,並且不明確考慮多個長寬比,我們就可以近似重現 YOLO。
Conclusions
本文介紹了SSD,一種用於多個類別的快速 single-shot object detector (單次物體檢測器)。我我們模型的一個主要特點是使用多尺度卷積 bounding box 輸出,並將其附加到網路頂部的多個 feature maps 上。這種表示方式允許我們能夠有效地,對可能的 box 形狀的空間進行建模。我們透過實驗驗證,在適當的訓練策略下,大量精心選擇的 default bounding boxes 可以提高效能。
我們建構的 SSD 模型的 box predictions sampling location、尺度和長寬比,比現有方法至少高一個數量級。我們證明,在相同的 VGG-16 基礎架構下,SSD 在 accuracy 和速度方面與最先進的物體偵測器相比具有優勢。我們的 SSD512 模型在 PASCAL VOC 和 COCO 上的準確性方面顯著優於最先進的 Faster R-CNN,同時速度提高了 3 倍。我們的即時 SSD300 模型以 59 FPS 的速度運行,這比目前的即時 YOLO 替代方案更快,同時產生明顯優越的檢測 accuracy。
除了其獨立的 utility (實用程式) 之外,我們相信我們的整體且相對簡單的 SSD 模型為採用物體檢測 component 的大型系統提供了有用的 building block。一個有前途的未來方向是探索其作為使用 recurrent neural networks 的系統的一部分的用途,以同時檢測和追蹤影片中的物體。
參考資料
Object Detection with Single Shot Multibox Detector – AI DIARY OF ZNREZA
Single Shot MultiBox Detector (SSD) 論文閱讀 | by 李謦伊 | Medium